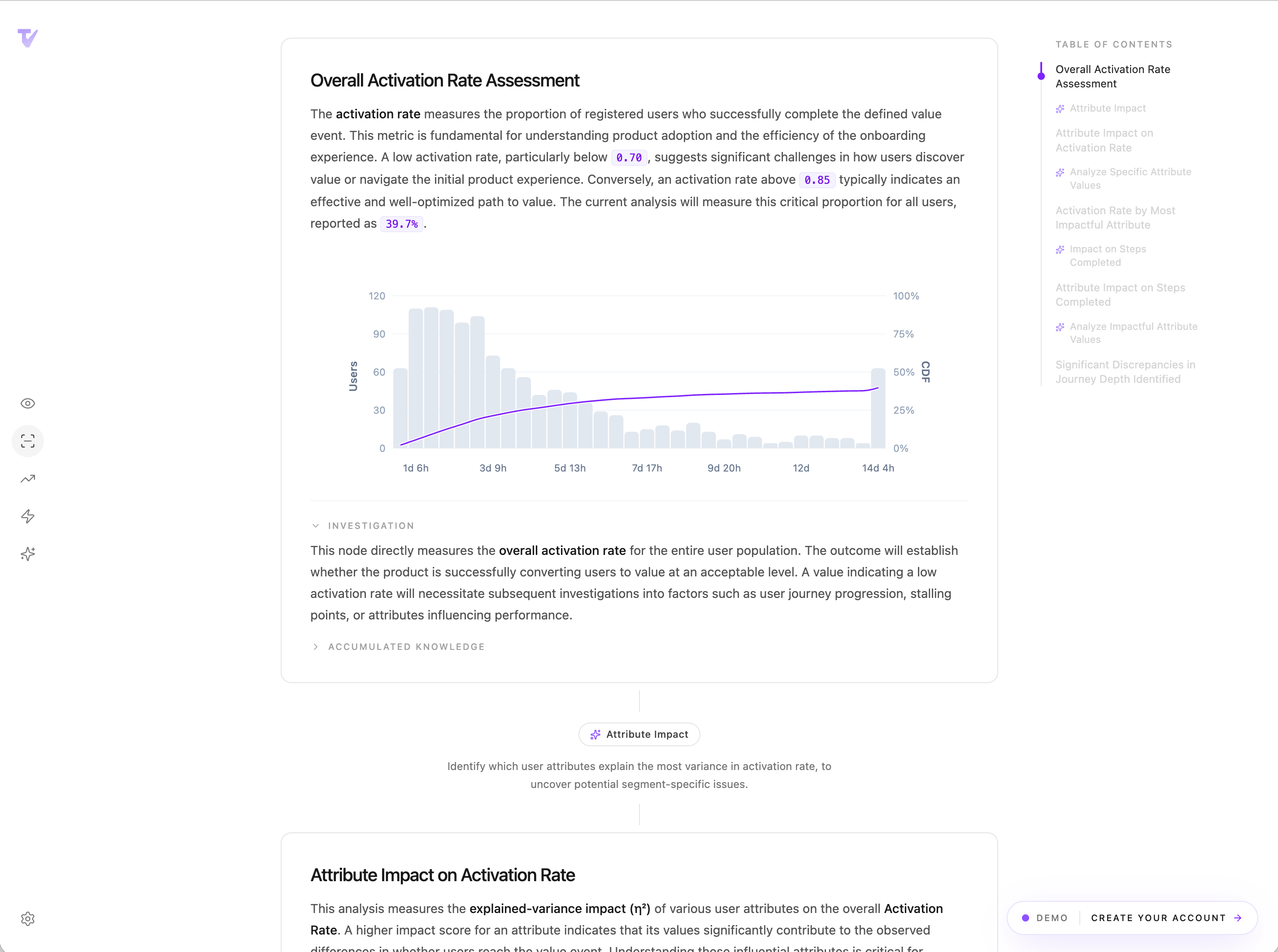
LLM reasoning,
deterministic execution.
Kapy turns natural-language questions into validated research plans that run as pure SQL on your warehouse. No hallucinations. No randomness. Auditable by default.
Trusted by teams building on deterministic AI
Why LLMs break in enterprise data environments
Conversational analytics looks magical in demos and fails in production.
Hallucination
LLMs invent columns, mistype joins, and produce queries that look right and return garbage.
Non-reproducibility
Ask the same question twice and get two different answers. Impossible to build workflows on top of.
Audit gap
Regulated environments demand traceability. 'The model decided' is not a valid explanation.
From question to SQL — with zero guessing in between.
Kapy separates LLM creativity (bounded and validated) from deterministic computation (pure SQL). The same research plan runs the same way — forever.
Define the domain
Typed function library for your schema
An AI agent walks your warehouse schema and proposes a typed function library that becomes your analytical vocabulary.
Compile the language
Grammar + JIT compiler
A formal Ohm.js grammar is compiled per tenant from the function library. Every LLM output is grammar-validated before execution.
Generate research plan
Bounded hypotheses, validated
The LLM writes research plans in your compiled language. Invalid expressions are auto-repaired up to three times.
Execute
Pure SQL, same result every time
Research plans compile to optimized CTE-based SQL. The LLM is off the runtime path. Bit-for-bit reproducible results.
New data, re-run
Same plan, fresh dataset — no AI needed
Swap the dataset, date range, or tenant. The same plan runs again with zero LLM calls. Pure SQL, instant results.
A typed language between English and SQL
KRL — Kapy Research Language — is a compiled DSL generated from your own function library. The LLM writes KRL, not SQL. Every KRL expression is grammar-validated before it ever touches your database.
- Type-safe set algebra (union, intersection, difference)
- Auto-repair on invalid expressions (up to 3 LLM repair passes)
- Compiles to optimized CTE-based SQL
- Per-tenant grammar customization
{
"conditions": [
"trend(churn_rate(clients('enterprise'))) > 0.1",
"usage_drop(clients('enterprise')) > 0.3",
"p90(ttv(fastTtv())) < p90(ttv(reached()))"
],
"conclusions": [
{
"when": ["C1", "C2"],
"title": "Enterprise churn driven by engagement collapse"
}
]
}Run it once. Run it a million times. Same answer.
The usual approach
- Probabilistic output
- Query varies between runs
- No audit trail
- LLM on critical path at runtime
Kapy
- Deterministic execution
- Bit-for-bit reproducible
- Every query traceable
- LLM off the runtime path
Perfect for compliance, finance, healthcare, and any workflow where 'the model decided' is not a valid answer.
Two ways to run Kapy
Embed in your SaaS
Add Kapy's research layer to your product in a day. A server-side bridge keeps your API key safe. React hooks and components do the rest.
Standalone platform
Give your data team a full research environment. Workspaces, versioned prompts, audit logs, and the Kapy UI out of the box.
- Managed cloud
- Self-hosted (K8s)
- On-prem available
How Tivalio runs product analytics on Kapy
Tivalio is a product analytics intelligence layer that helps teams understand why users reach value late — or never — and what differentiates fast activators from the long tail.
The challenge: product teams need reproducible investigation workflows, not ad-hoc dashboards. Averages hide structure. The long tail is the signal.
How Kapy solves it: Tivalio embeds the Kapy SDK and UI components. Every investigation is a versioned research plan running deterministic SQL. Analysts ask, Kapy computes, results are bit-for-bit reproducible.
Visit tival.io“Kapy lets us ship activation research that's as reproducible as our unit tests.”
Building the execution layer for enterprise AI
Kapy was founded in 2025 with a single conviction: the bottleneck in enterprise AI is not reasoning capability — it's execution integrity. Language models are extraordinary at proposing research hypotheses. They are not suitable for running the queries that answer them. Kapy closes that gap with a compiled intermediate language that makes LLM plans verifiable, reproducible, and safe to run on real data. We're building the standard layer for teams that refuse to choose between AI creativity and engineering rigor.
Sergio Ramírez
Founder & CEO
Software engineer with deep experience in data-intensive systems, LLM infrastructure, and developer tooling. Previously built and shipped analytics products used by product teams at growing SaaS companies. Founded Kapy to bring engineering-grade reliability to AI-assisted data investigation.
Enterprise questions, answered
Kapy connects to your warehouse via a connection string you control. Nothing is copied. Queries run where your data lives.
Yes. The engine, worker, API, and UI ship as containers with Kubernetes manifests. On-prem is supported.
PostgreSQL today. BigQuery and Snowflake interpreters are on the roadmap — the engine is designed for multiple backends via a clean interpreter abstraction.
OpenAI, Anthropic, Google, Grok, Groq — all behind a unified abstraction layer. You can bring your own keys, swap providers, or run in a provider-agnostic mode.
Yes. Once a research plan exists, execution is pure SQL. Running it a thousand times produces bit-for-bit identical results.
Text-to-SQL lets the LLM write raw SQL — anything goes. KRL is a typed, compiled language generated from your function library. The LLM can only write expressions the grammar accepts. Invalid output is auto-repaired.
Workspace-isolated tenancy, bearer-token auth with server-side bridge for SDK integrations, audit trail on every execution. SOC2 track in progress.
Enterprise contracts based on workspace count and execution volume. Contact us for a quote.
Embed safe AI execution today
Offered as an embeddable engine (SDK) or a standalone platform for your data teams.